.svg)
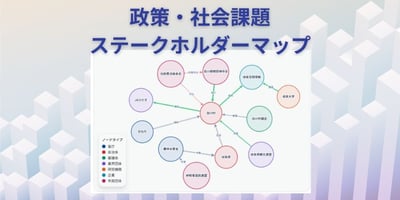
はじめに 公共政策や社会課題は多くの人たちが関わるものであり、多くのステークホルダーがいます。その方々とコミュニケーションをうまく取れなければ、政策は良くなりませんし、実現もできません。...

はじめに
政策アイデアを考える際に、多様な観点からの意見や論点を把握することはとても重要です。
そこで PEP では、最新の大規模言語モデル(LLM)を活用することで、政策テーマごとに多様なステークホルダー(利害関係者)を自動生成し、それぞれの立場を持つ AI エージェント同士が仮想的な熟議を行う Web アプリのプロトタイプを作りました。
このプロトタイプを使うことで、自分の作った政策アイデアの改善点を知れるほか、論争中の政策に対しての多様な意見があることに気づくことができ、自分自身の政治や政策に対する意見をある程度客観視することもできると考えています。

今回 PEP で開発したこのプロトタイプでは、ユーザーが日本語で任意の政策アイデアを入力すると、LLM がその政策に関心を持つであろう複数のステークホルダーのペルソナを自動生成します。各ステークホルダーは、社会的立場や利害、価値観に基づいた独自の視点を持ち、ユーザーが選択したステークホルダー同士がチャット形式でリアルタイムに議論を展開します。

議論の流れや各ステークホルダーの主張は、画面上で縦に連続して表示され、実際のラウンドテーブルディスカッションを覗いているかのような体験が可能です。最終的には、議論内容をもとに政策提言や論点整理が自動生成され、ユーザーが熟議の成果を確認できる設計となっています。
以前、政策案の検討初期段階においてステークホルダーの反応を探る際に、生成 AI を活用することで調査の効率化を図る手法を、本ブログの記事で紹介しました。今回紹介する Web アプリではその手法を更に発展させ、生成 AI によるステークホルダー同士の議論を行わせることにによって、潜在的な対立関係や利害関係、政策案に対する論点や意見の収集をよりやりやすくしました。
使い方
こちらのツール説明動画もご参照ください。
まずは、以下の本 Web アプリ URL にアクセスしてください。
https://pep-ai-stakeholder-discussion.replit.app/
(※本アプリは予告なく公開停止することがあります)
上記 URL にアクセスすると、政策アイデアを入力する画面に移行します。画面下部の「サンプル」ボタンから、サンプルとして用意されている政策アイデアを入力することも可能です。
政策アイデアを入力したのち、「ステークホルダーを生成」ボタンをクリックすることで、生成 AI が入力された政策に関連するステークホルダーを複数生成します。

この後の議論に参加させたいステークホルダーにチェックを入れてください。また、ペンのアイコンをクリックすることで各ステークホルダーの編集が可能です。ステークホルダーを選択した後に「討論を開始」ボタンをクリックすることで討論が開始されます。

討論が終了すると、自動的に討論結果のサマリー画面に移行します。こちらのページは討論ごとに固有の URL が発行される仕組みとなっており、SNS などで結果をシェアすることが可能です。
注意点:AI ステークホルダーのバイアスについて
本アプリで生成されるステークホルダーやその発言は AI (Gemini 2.5 Flash)により生成されたものであり、実際のステークホルダーの意見とは異なる発言が生成される可能性や、考慮すべき重要な論点が見落とされる可能性があります[1]。本アプリの生成結果はあくまで初期の政策検討段階で参考資料として補完的に用いることにとどめ、実際のステークホルダーへの聞き取りを本アプリの使用で代替しないことを強く推奨します。
AI ステークホルダー間の熟議の望ましいあり方とは?
本アプリを設計する際に問題となったのは、「AI 同士の議論をどのように設計するか?」という点です。議論の目的の設計や場づくり、参加者の選定は人間のステークホルダー同士での議論においても重要ですが、AI ステークホルダー同士で議論を行わせる場合は「どのような情報をもとに、どのような観点から発言するか」を設計時にプロンプトとして指定する必要があるため、明確に意識して設計することが自ずと求められます。
本アプリでは、ステークホルダー同士の議論を通じて多様な論点を浮かび上がらせることを目指しました。具体的には、ステークホルダー生成時は「(まだ産まれていない未来世代も含むような)多様なステークホルダーの生成」を行うよう指示し、議論の際には安易な妥協策に走らず、あくまで政策に対する自身の立場(支持、反対、中立等)を維持しながら議論に建設的な貢献を行うよう指示しています。
実際に使用しているプロンプトは以下の通りです。
ステークホルダー生成時のプロンプト:
# 政策討論ステークホルダー生成プロンプト
## あなたの役割
あなたは政策分析の専門家です。与えられた政策について、現実的で多様な観点から議論できる6人のステークホルダーを生成してください。
## 地域性の考慮
- **対象地域**:
- **地域性の反映**: ステークホルダーはその地域に在住・在勤する人物として設定
- **地域特有の視点**: その地域の文化、経済状況、地理的特徴に基づいた視点を組み込む
## 発言スタイルの多様性
各ステークホルダーには以下の性格的な発言スタイルを割り当て、一貫性を保つこと:
- **丁寧語タイプ**: 一貫して敬語・丁寧語を使用 (例:「検討が必要と考えます」「ご理解いただけますでしょうか」)
- **カジュアル語タイプ**: 親しみやすく自然な口調 (例:「そこは大事だよね」「みんなで考えよう」)
- **乱暴な語彙タイプ**: 直接的で強い表現を使う (例:「そんなの無理だ」「全然納得できない」)
- **おとなしい言葉遣いタイプ**: 控えめで穏やかな表現 (例:「〜かもしれません」「〜と思うのですが」)
- **命令・指示タイプ**: ストレートに行動を促す言い回し (例:「やれ」「してください」「しなさい」)
## 必須要件
### 人数とバランス
現役世代を5人、将来世代を1人作る。
#### 現役世代
- **総人数**: 5人
- **政策スタンス**: 支持者、反対者、中立者をなるべく均等にバランス
- **世代カテゴリ**: 「現役世代」を指定
- **職業カテゴリ**: 行政、企業、市民、専門家、学術機関、NPOのいずれかを均等にバランス
- **生まれ年**: 1950年 ~ 2015年までを分散させる。
- **年齢**: 10歳 ~ 80歳を均等にバランス。
- **性別**: 男女比を考慮(3:3または4:2)
#### 将来世代
- **総人数**: 1人
- **世代カテゴリ**: 「将来世代」を指定
- **政策スタンス**: 支持者、反対者、中立者の中で、適切なものを将来世代の利益を考えて指定
- **カテゴリ**: 「将来世代」を指定
- **組織**: 行政、中小企業、個人事業主のいずれか
- **職業**: サラリーマンもしくは個人事業主
- **生まれ年**: 2040年 ~ 2100年生まれのどれか
- **年齢計算ルール**: 必ず「成人時期(生まれ年+25歳)」での年齢を設定(例:2055年生まれ → 2080年で25歳 → 「20代後半」)
- **発言時点**: 成人時期(生まれ年+25歳)を基準とし、役職もその時点での設定とする
- **性別**: 現役世代の男女比を考慮してバランス
### 品質基準
- **現実性**: 実在しそうな具体的な人物設定
- **多様性**: ステレオタイプを避けた複雑な人物像
- **関連性**: 政策内容に実際に関わりそうな職業・立場
- **一貫性**: 背景と価値観・発言スタイルの整合性
- **時間的視点**: 残り寿命や将来世代の視点からの発言
- **口調統一**: 各人物の speaking_style は一貫しており、丁寧語・カジュアル語・乱暴な語彙・おとなしい言葉遣いが混在しない
## 各ステークホルダーの必須項目
### 基本情報
- **name**: 日本人のフルネーム(地域に応じた名前を考慮する。未来という言葉は入れない)
- **age**: 年齢層(例:30代前半、50代後半)
- **role**: 具体的な職業・役職(組織名も含む、地域に存在する組織を想定)。未来世代の場合は学術機関以外を指定。
- **category**: 行政/企業/市民/専門家/学術機関/NPO
### 詳細プロフィール
- **background**: 200-300文字の詳細背景(出身・経歴・家族・活動歴)
- **expertise_details**: 専門分野の具体的な詳細
- **notable_achievements**: これまでの注目すべき実績・経験
- **current_concerns**: 現在抱えている主要な懸念事項
### 発言特性
- **speaking_style**: 発言の口調・話し方の特徴
- **key_phrases**: よく使う表現・キーワード(配列2-3個、発言スタイルと統一感を保つ)
- **debate_attitude**: 議論への取り組み方(建設的/対立的/協調的等)
- **flexibility**: 意見の柔軟性(高/中/低)
### 価値観・動機
- **core_values**: 核となる価値観(配列2-3個)
- **problem_solving_style**: 問題解決への取り組み方
- **influence_style**: 他者への影響力の行使方法
- **persuadability**: 他者からの説得に応じる度合い(高/中/低)
### 政策に対する立場
- **policy_stance**: 政策への基本姿勢(支持/反対/中立)
- **main_expectations**: 政策に対する主な期待・希望
- **key_concerns**: 政策に対する主要な懸念・不安
- **negotiable_points**: 交渉・妥協可能なポイント
- **likely_allies**: 賛同・協力しそうな他の立場
- **potential_conflicts**: 対立・衝突しそうな他の立場
- **perspective**: この政策への総合的視点(100-150文字)
ステークホルダーによるコメント生成時のプロンプト:
上記プロンプトで生成したステークホルダーの背景情報、および過去の討論履歴に加え、以下の指示を与えています。
CRITICAL: 政策立場「${stakeholder.policy_stance}」を必ず反映してください!
- 支持の場合: 政策の利点を強調し、建設的な改善提案
- 反対の場合: 政策の問題点、リスク、代替案を具体的に指摘
- 中立の場合: バランス良い視点で条件付き賛成や課題を指摘
【重要な発言要件】
- 120-180文字で、他参加者の発言に具体的に反応し、議論を前進させてください
- 前回の発言と異なる新しい論点・角度から議論を深めてください
- 単純な賛成・反対の繰り返しではなく、建設的な議論展開を心がけてください
- 具体的な事例、データ、経験を引用して説得力を高めてください
- 感謝の表現(「皆さんの意見に感謝します」「ありがとうございます」など)は省略し、内容に集中してください
また、人間同士の議論の際にはアイコンタクト等を通じて自然と行われる話者の交代(ターン・テイキング)についても、本アプリでは意識的な設計を行う必要があります。今回は、各ステークホルダーの発言量を均等にするために、順番に計3回の発話を行うというシンプルな設計となっています。とはいえ AI 同士の会話におけるターン・テイキングの手法は他にも多く提案されており、例えば他の話者に対する問いかけを行ったり、「今発言するべきか、もしくは静観すべきか」を各 AI ステークホルダー自身が判断し発話意欲の高い AI ステークホルダーが発言を行う、といったような手法(Nonomura & Mori, 2025) も考えられます。そのような手法を用いることでより「人間らしい」議論が期待できる可能性がある一方で、一部の話者によって議論の内容が支配されるリスクも考えられます。
ここまで見てきたように、本アプリのような生成 AI によるステークホルダー同士の議論を設計するにあたっては、最終的な出力の質や方向性を左右しうる様々な変数が存在します。今回のアプリでは、それぞれの条件について比較対照し、「どのような条件や議論設計が最適か」を探るような実験は行っていません。あくまでコンセプト検証としてのプロトタイプの公開であることをご理解いただければ幸いです。
おわりに
本アプリを活用することで、政策アイデアの検討段階における多様な視点の確保や、論点の洗い出しが効率化されることを期待します。また、本アプリを使うと、様々なステークホルダーの観点を仮想的に把握しやすくなるため、教育現場での活用においても一定の効果を上げられるのではないかと思われます。そして現在社会で論争になっているような政策や意見を、本アプリで複数の視点から見てみて客観視することで、政策に関する心の痛むような論争が減ることも願っています。
なお、AI の出力には偏りや限界があるため、本アプリの出力を鵜呑みにせず、人間による批判的検証や多角的な議論を重ねることが不可欠です。その点についても、最後に強調させていただければと思います。
本プロトタイプを活用された際にはぜひ pep@ihj.global やお問い合わせフォームまでご一報ください。
脚注
[1] 大規模言語モデル(LLM)の出力にバイアスが含まれる可能性があることはこれまで多く指摘されています。LLM の英語での出力については、マイノリティの立場の意見を表現する際に質が落ち(Santurkar et al., 2023)、場合によってはマイノリティの特徴を過度に強調するような出力がなされる(Cheng et al., 2023)ことが知られています。また、今回のアプリで使用した Gemini などの商用 LLM の多くが左派的な返答を行う傾向にあることも知られています(Westwood et al., 2025)。
参考文献
- Cheng, M., Piccardi, T., & Yang, D. (2023). CoMPosT: Characterizing and evaluating caricature in LLM simulations. arXiv preprint arXiv:2310.11501. https://doi.org/10.48550/arXiv.2310.11501
- Nonomura, R., & Mori, H. (2025). Who speaks next? Multi-party AI discussion leveraging the systematics of turn-taking in Murder Mystery games. Frontiers in Artificial Intelligence, 8, 1582287. https://doi.org/10.3389/frai.2025.1582287
- Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023, July). Whose opinions do language models reflect?. In International Conference on Machine Learning (pp. 29971-30004). PMLR. https://proceedings.mlr.press/v202/santurkar23a.html
- Westwood, S. J., Grimmer, J., & Hall, A. B. (2025). Measuring Perceived Slant in Large Language Models Through User Evaluations. https://www.gsb.stanford.edu/faculty-research/working-papers/measuring-perceived-slant-large-language-models-through-user
%20-%20Copy%20-%20Copy-1.jpg?width=50&name=Umada_api%20(1)%20-%20Copy%20-%20Copy-1.jpg)